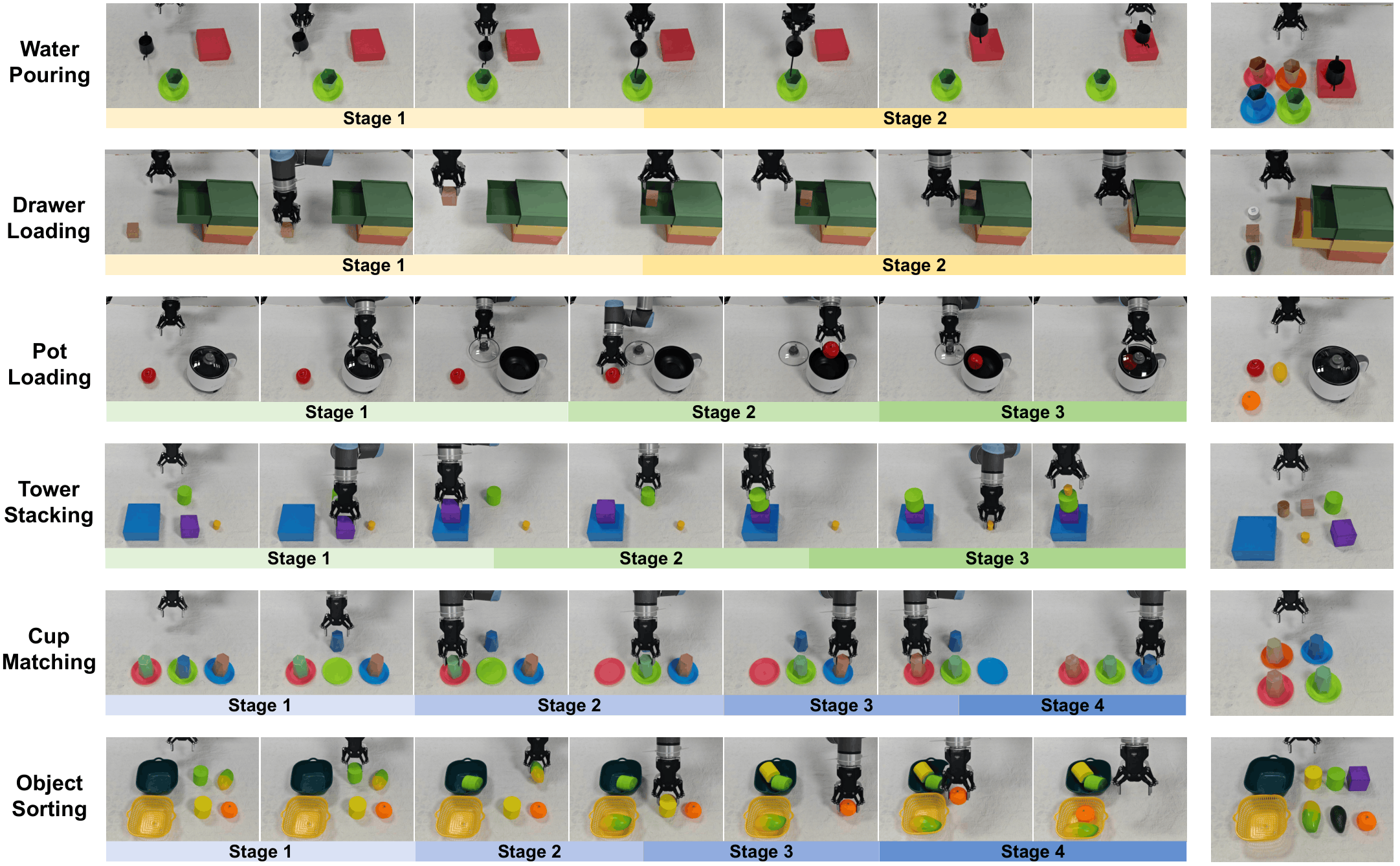
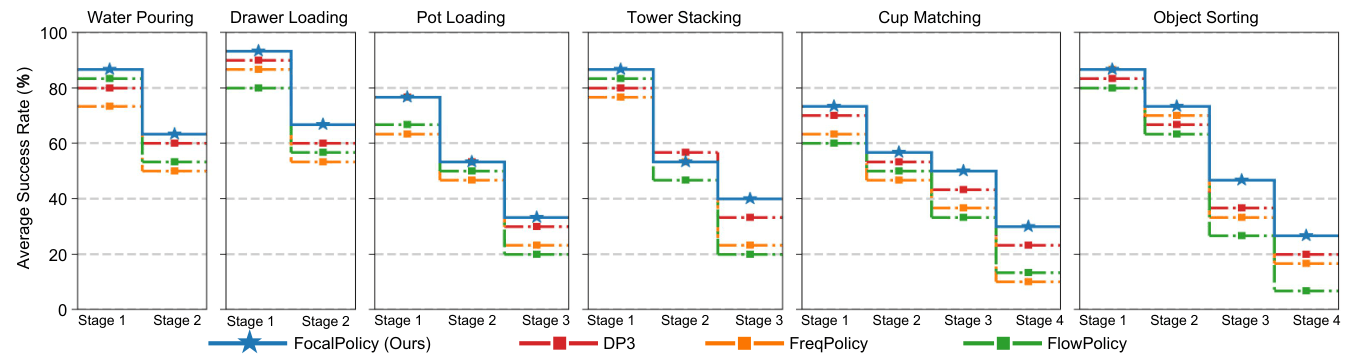
Motivation & Comparison
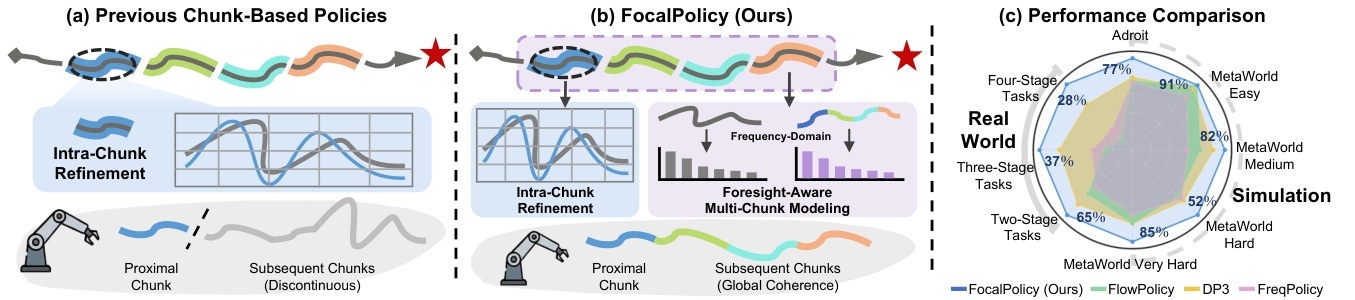
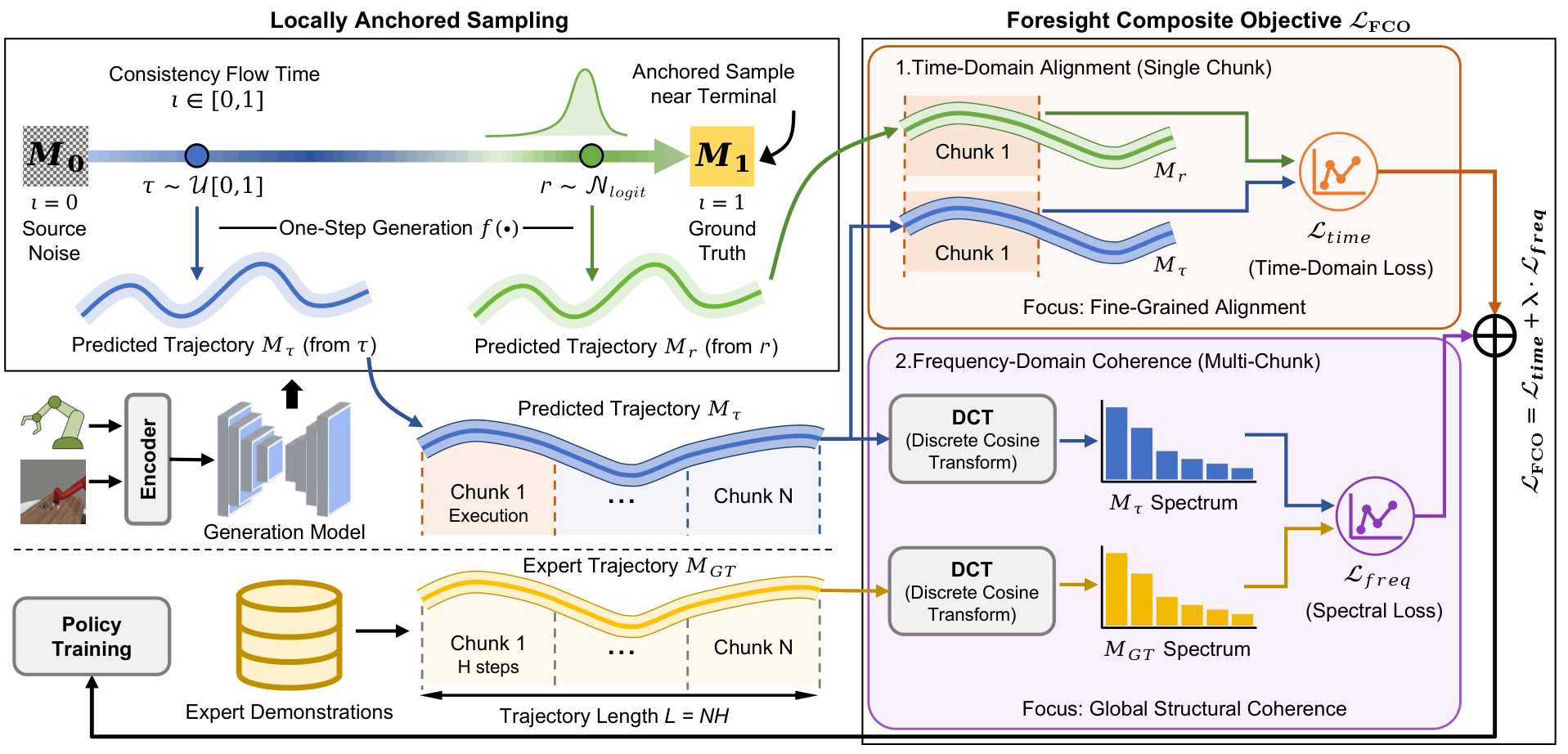
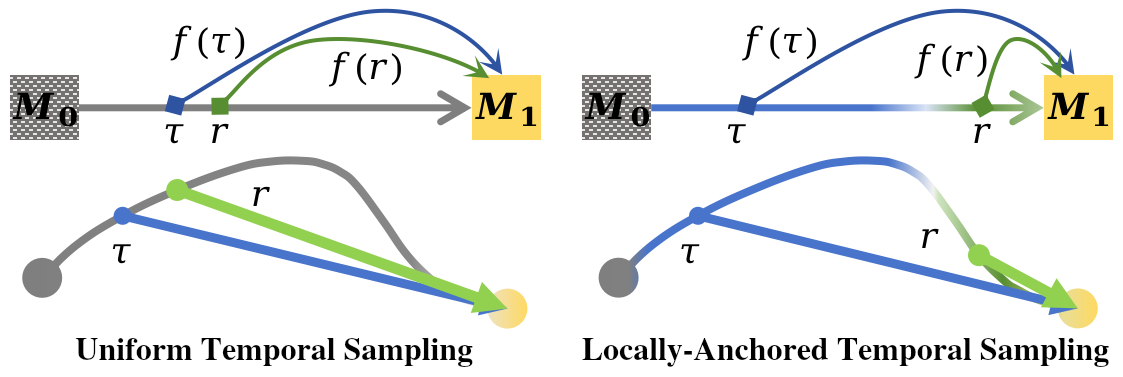
Comparison: Previous chunk-based policies (left) vs. FocalPolicy (right). FocalPolicy employs a Foresight Composite Objective to synergize proximal precision with distal coherence across chunks.
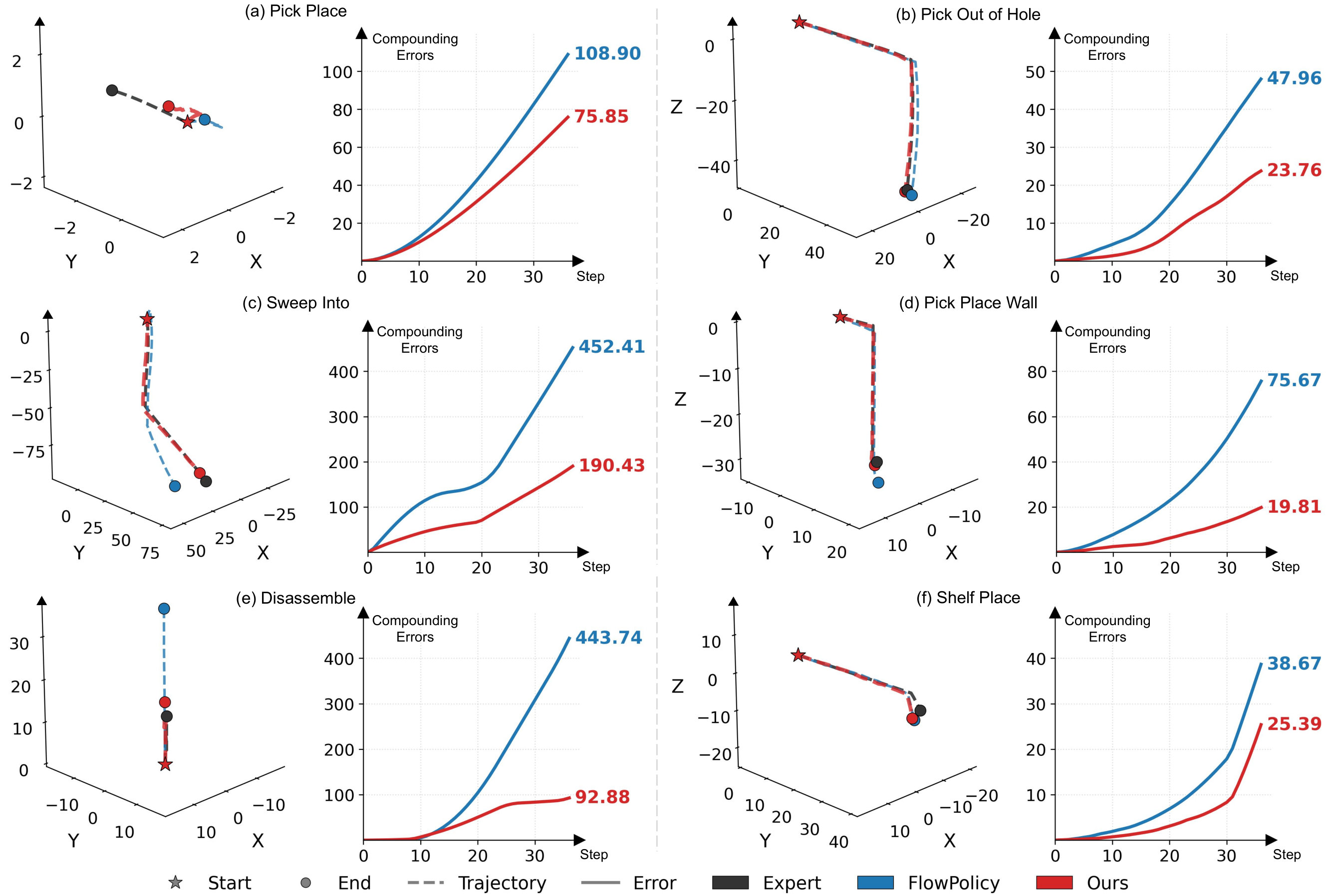
Current imitation learning-based policies adopt action chunking to mitigate compounding errors. However, frameworks like Consistency Flow Matching (CFM) typically focus entirely on optimizing intra-chunk refinement. Because they overlook inter-chunk discontinuities, they struggle to perceive global motion trends. This leads to disjointed execution and compounding errors over sequential stages.
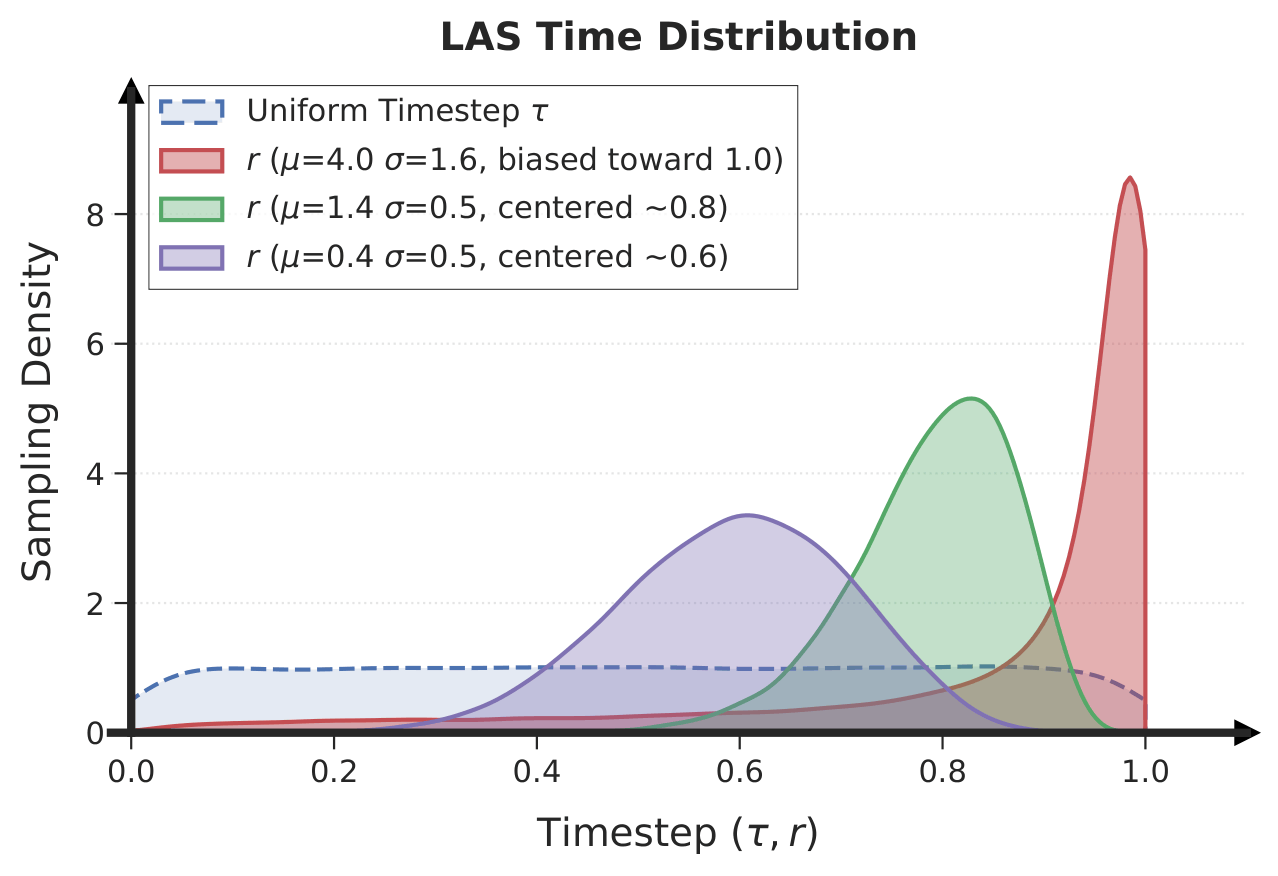
FocalPolicy shifts the paradigm from single-chunk refinement to foresight-aware multi-chunk modeling. By utilizing prioritized learning, the policy ensures fine-grained fidelity for proximal actions while maintaining coarse structural coherence for distal trajectories.